
Dienekes Pontikos' Dodecad Project is getting more accurate week after week. The current admixture results can already shed some light on a few of the great question marks in population genetics.
Y-DNA only gives a very partial picture of historical population movements. My hypothesis is that some Y-chromosome haplogroups do produce more male offspring than others, so that their frequency naturally increase in relation to other haplogroups. I believe that this is the case of at least haplogroups R1a1a and R1b1b2a.
The Indians
Just how much (Indo-)European blood is there in the Indian subcontinent ? Haplogroup R1a can peak over 70% of male lineages in some parts of Pakistan or in some Brahmin communities. Overall, it ranges between 40 and 55% of all lineages in Pakistan and North India. Add to this West Asian haplogroups like G and J, and one could be fooled into believing that half of the Indian and Pakistani gene pool comes from Europe of the Middle East. Autosomal DNA completely disproves this.
It would seem that European DNA amounts to a meagre 1 to 5% of the gene pool in South Asia, with the exception of the Pathans who have a slightly higher percentage (7%). However this is not the whole picture. The Dagestan component (ranging from 7 to 15% in Pakistan, North India and South Indian Brahmins) most probably reflects a North Caucasian admixture dating from the Indo-European migrations. Altogether, the Indo-European admixture (Dagestan + European) amounts to 26.3% for the Pathans, 14.7% for the Sindhi, 13.8% for the Andra Pradesh Brahmins, 12.6% for the Tamil Brahmins, 9% for the Gujarati, 6% for the Balochi, 3.3% for the North Kannadi, and is almost null for the lower caste and tribal Indians.
There is also the West Asian component, which in all likelihood represents the spread of agriculture from the Caucasus and northern Mesopotamia towards Central and South Asia. There is a clear west-east gradient in the West Asian component, starting at over 70% in the South Caucasus and northern Iraq and 65% in Iran, and falling sharply to 10% in Balochistan (West Pakistan), 6.5% among the Pathans (Afghanistan-North Pakistan), 3.5% in Sindh (South-East Pakistan), and a mere 2% in Gujarat (West India, at the border of Sindh).
The Pakistan component
The small percentage belonging to the Pakistan component in Europeans is surely mis-attributed and more likely another Indo-European element. I am not saying that the whole Pakistan component is Caucasian or European in origin, but rather that it could and should be sub-divided and will in all probability spawn a new component matching all the European, most of the Caucasian and part of the South Asian admixture now labelled as Pakistan. This is obvious from the 3-way admixture graph.


For example, the Balochi are 70.7% Pakistani, 7.7% Indian, 2.1% North Kannadi, and 1.2% Irula; in total they should be 81.7% South Asian in the admixture-3 graph, but they are only 40% South Asian. This means that about 30% of the Pakistan component is really South Asian, but 40% is West Eurasian.
Note that the Pakistan component is very low in tribal, Dravidian and lower caste Indians, though a bit higher than the European and Dagestan components. Yet it is quite important among the Brahmins (18.5%), and even exceeds the total of the West Asian, Dagestan and European components. I wouldn't be surprised if this over half of this Pakistan component was in fact of Indo-European origin. This would explain why it is found in Europe, in the Caucasus and among Brahmins. If the Pakistan component can be divided, the part corresponding to a West Eurasian origin could be called "Aryan", or even merged with the Dagestan component.
Relation with Y-DNA haplogroups
The Neolithic West Asian component was most likely carried by members of haplogroups G and J2.
The Bronze-Age Indo-European invaders were probably a hybrid group of North Caucasians (Dagestan) carrying haplogroups G2a3b1a, R1b1b and R1a1a, and southern Russian R1a1a (here represented by the European component). The North Caucasian group would have merged with the Russian group in the Volga-Urals region (Sintashta-Poltavka culture), prior to conquering Central Asia (Andronovo culture) as far as northern Pakistan, then brought their armies to northern India.
However, the percentage of the European R1a is completely out of proportion with the actual European blood in South Asia (unless European blood is hidden in the Dagestan and Pakistan components). I think that the explanation is similar to that of the R1b dominance in Western Europe. In summary :
Likely reasons why R1a became dominant in South Asia
1) R1a produces a slightly higher percentage of male offspring than other haplogroups, which has for effect an exponential increase in R1a lineages over time.
2) Until recently, sultans and maharajahs in India and Pakistan have had a tradition of having harems. The largest could hold over one hundred concubines. It was not uncommon therefore for rulers to have many dozens of children.
Furthermore, the Indian subcontinent has long been divided in hundreds of small kingdoms, where each ruler had his own harem. Had India been mostly unified under a single emperor with a single harem like in China, the impact on the overall population would have been far smaller.
If this polygamous system goes back to ancient times (e.g. the Indo-European conquest of South Asia 4000 years ago), it is easy to see how a fairly small group of aristocrats could have fathered 40% to 60% of male lineages in the region.
Concretely, if the Aryan nobility had in average three times more descendants than men from the populace (a very conservative estimate), in a stable population, a 1% minority of paternal lineages would turn into a 30% minority in only ten generations. Naturally, if the wives and concubines were taken mostly from the local population, only a small fraction of the conquerors' autosomal DNA would survive after 40 centuries. This is exactly what we witness today.
Explanations as to why autosomal European DNA is so low compared to European Y-DNA in South Asia
1) The Indo-European speakers from Russia who carried the original R1a lineages first mixed with Central Asian populations (who were probably closer to South Asian and West Asian ones at the time) before conquering India. This explains why the percentage of both R1a and European autosomal DNA is higher around Afghanistan, Tajikistan and northern Pakistan, then decreases progressively towards southern an eastern India.
2) Indo-European conquerors probably took a lot of native wives in the early years, which further diluted the European autosomes while keeping hg R1a high. I expect that the same thing happened with R1b among the Basques.
Some people have advanced the possibility that R1a was already present in India long before the Bronze Age, in Paleolithic times. Phylogenetic studies, though, point at a South Siberian origin of R1a, which I think is too remote from India to support such a hypothesis. Indian R1a lineages show less divergence than those in Central Asia, Russia or the Balkans. Although Indian R1a is quite varied, this kind be better explained by the huge historical population of India. More births create more mutations. This should be considered when calculating the time to the most recent common ancestor. The Indian subcontinent is at least 10 times more numerous than southern Russia and Siberia nowadays, and certainly held an even greater proportions in the past, before modern agricultural techniques, modern transportations and modern housing allowed for higher densities of population in very cold and isolated regions.
The Turks
Here the 7% of Siberia and East Asian haplogroups of probable Turkic origin (C, N, O, Q) corresponds quite well to the 6% of Siberian and East Asian autosomal DNA. Likewise, the roughly 5% of typical South Asian haplogroups (H, L, R2) are not far off the 3.5% of Indian and Dravidian (Irula and North Kannadi) admixture. Both were of course a bit diluted.
This graph shows a clearer picture, with about 3% of South Asian, 4% of Northeast Asian and 2.5% of East Asian.

Turkey is a good example of how an ethnic minority can impose its language on a vast territory (Turkic languages originated in the Altai region of Siberia near Mongolia).
The Iberians
There has long been a controversy (on this forum) about the origin of African haplogroups (E-M81 or mtDNA L) in southern and western Iberia in particular. Autosomal admixture confirm a small but substantial percentage of both Northwest African (5.7%) and East African (1.8%) DNA among the Portuguese. Spaniards have in average 2.2% of Northwest African DNA, 0.6% of East African and 0.2% of West African. The Basques, who have nearly no African Y-DNA or mtDNA, lack completely African autosomes.
Portugal
The Portuguese have in total 7.5% of African autosomal DNA, which matches the percentage of African Y-DNA. According to the Adams et al. study of Iberian Y-DNA, North Portugal has 3% of E1b1b1b (E-M81) and 3% of sub-Saharan African E1. South Portugal has 8% of E-M81 and 1% of E1b1a. This gives an average of exactly 7.5% of African Y-DNA for Portugal.
4.5% of the Portuguese autosomes originated in Southwest Asia (I.e. the Arabian peninsula, Levant and southern Mesopotamia). Haplogroups corresponding to this region are E1b1b1a (E-M78), E1b1b1c (E-M123), J1 and T. To facilitate the breakdown I will consider G2a and J2 as West Asian, and L as South Asian. Still based on Adams et al., the North Portuguese have in total 11% of Southwest Asian haplogroups, against 16% for the South Portuguese. In this case the Y-DNA exceeds the actual autosomal percentage. This is almost certainly because Southwest Asian were already a melting pot of populations, that included some European blood. The Dodecad admixtures show that the Syrians, Jordanians and Egyptians have between 15% and 20% of South European DNA.
The same thing can be observed with West Asian haplogroups (G2a, J2), which make up 19% of lineages in North Portugal and 24% in South Portugal, but only reach 7% of autosomal DNA.
Here are the admixtures of Portuguese Dodecad members.
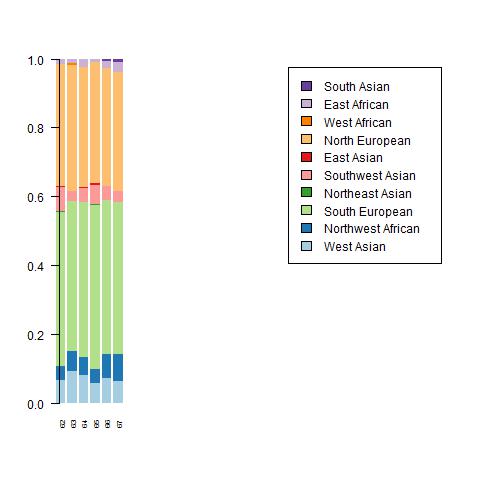
Spain
The Spanish have 3% of African autosomal DNA, which is roughly equal to the proportion of E-M81.
Spaniards have been much less influenced by the Middle East than Portugal, except for the regions of Extremadura, Andalusia, Murcia and Valencia. In average they carry only 3.3% of Southwest Asian autosomal DNA, and 8.5% of West Asian one. This is more in agreement with Y-DNA (roughly 5% from Southwest Asia and 7% from West Asia) than in Portugal. But it would be interesting to compare Dodecad results region by region.
Analysis
It is not surprising to find a high percentage of Southwest Asian DNA in Portugal and southern Spain considering the importance that the Levant and Arabia played in the local history, starting with the establishment of Neolithic farmers some 8000 years ago, then the Phoenician colonisation, and finally the Arabic conquest of Al-Andalus.
The ratio of northern vs southern European DNA is about half-half for Portugal and 1/3 northern, 2/3 southern for Spain. This supports the theory of a denser Germanic in Portugal than in Spain.
Y-DNA only gives a very partial picture of historical population movements. My hypothesis is that some Y-chromosome haplogroups do produce more male offspring than others, so that their frequency naturally increase in relation to other haplogroups. I believe that this is the case of at least haplogroups R1a1a and R1b1b2a.
The Indians
Just how much (Indo-)European blood is there in the Indian subcontinent ? Haplogroup R1a can peak over 70% of male lineages in some parts of Pakistan or in some Brahmin communities. Overall, it ranges between 40 and 55% of all lineages in Pakistan and North India. Add to this West Asian haplogroups like G and J, and one could be fooled into believing that half of the Indian and Pakistani gene pool comes from Europe of the Middle East. Autosomal DNA completely disproves this.
It would seem that European DNA amounts to a meagre 1 to 5% of the gene pool in South Asia, with the exception of the Pathans who have a slightly higher percentage (7%). However this is not the whole picture. The Dagestan component (ranging from 7 to 15% in Pakistan, North India and South Indian Brahmins) most probably reflects a North Caucasian admixture dating from the Indo-European migrations. Altogether, the Indo-European admixture (Dagestan + European) amounts to 26.3% for the Pathans, 14.7% for the Sindhi, 13.8% for the Andra Pradesh Brahmins, 12.6% for the Tamil Brahmins, 9% for the Gujarati, 6% for the Balochi, 3.3% for the North Kannadi, and is almost null for the lower caste and tribal Indians.
There is also the West Asian component, which in all likelihood represents the spread of agriculture from the Caucasus and northern Mesopotamia towards Central and South Asia. There is a clear west-east gradient in the West Asian component, starting at over 70% in the South Caucasus and northern Iraq and 65% in Iran, and falling sharply to 10% in Balochistan (West Pakistan), 6.5% among the Pathans (Afghanistan-North Pakistan), 3.5% in Sindh (South-East Pakistan), and a mere 2% in Gujarat (West India, at the border of Sindh).
The Pakistan component
The small percentage belonging to the Pakistan component in Europeans is surely mis-attributed and more likely another Indo-European element. I am not saying that the whole Pakistan component is Caucasian or European in origin, but rather that it could and should be sub-divided and will in all probability spawn a new component matching all the European, most of the Caucasian and part of the South Asian admixture now labelled as Pakistan. This is obvious from the 3-way admixture graph.


For example, the Balochi are 70.7% Pakistani, 7.7% Indian, 2.1% North Kannadi, and 1.2% Irula; in total they should be 81.7% South Asian in the admixture-3 graph, but they are only 40% South Asian. This means that about 30% of the Pakistan component is really South Asian, but 40% is West Eurasian.
Note that the Pakistan component is very low in tribal, Dravidian and lower caste Indians, though a bit higher than the European and Dagestan components. Yet it is quite important among the Brahmins (18.5%), and even exceeds the total of the West Asian, Dagestan and European components. I wouldn't be surprised if this over half of this Pakistan component was in fact of Indo-European origin. This would explain why it is found in Europe, in the Caucasus and among Brahmins. If the Pakistan component can be divided, the part corresponding to a West Eurasian origin could be called "Aryan", or even merged with the Dagestan component.
Relation with Y-DNA haplogroups
The Neolithic West Asian component was most likely carried by members of haplogroups G and J2.
The Bronze-Age Indo-European invaders were probably a hybrid group of North Caucasians (Dagestan) carrying haplogroups G2a3b1a, R1b1b and R1a1a, and southern Russian R1a1a (here represented by the European component). The North Caucasian group would have merged with the Russian group in the Volga-Urals region (Sintashta-Poltavka culture), prior to conquering Central Asia (Andronovo culture) as far as northern Pakistan, then brought their armies to northern India.
However, the percentage of the European R1a is completely out of proportion with the actual European blood in South Asia (unless European blood is hidden in the Dagestan and Pakistan components). I think that the explanation is similar to that of the R1b dominance in Western Europe. In summary :
Likely reasons why R1a became dominant in South Asia
1) R1a produces a slightly higher percentage of male offspring than other haplogroups, which has for effect an exponential increase in R1a lineages over time.
2) Until recently, sultans and maharajahs in India and Pakistan have had a tradition of having harems. The largest could hold over one hundred concubines. It was not uncommon therefore for rulers to have many dozens of children.
Furthermore, the Indian subcontinent has long been divided in hundreds of small kingdoms, where each ruler had his own harem. Had India been mostly unified under a single emperor with a single harem like in China, the impact on the overall population would have been far smaller.
If this polygamous system goes back to ancient times (e.g. the Indo-European conquest of South Asia 4000 years ago), it is easy to see how a fairly small group of aristocrats could have fathered 40% to 60% of male lineages in the region.
Concretely, if the Aryan nobility had in average three times more descendants than men from the populace (a very conservative estimate), in a stable population, a 1% minority of paternal lineages would turn into a 30% minority in only ten generations. Naturally, if the wives and concubines were taken mostly from the local population, only a small fraction of the conquerors' autosomal DNA would survive after 40 centuries. This is exactly what we witness today.
Explanations as to why autosomal European DNA is so low compared to European Y-DNA in South Asia
1) The Indo-European speakers from Russia who carried the original R1a lineages first mixed with Central Asian populations (who were probably closer to South Asian and West Asian ones at the time) before conquering India. This explains why the percentage of both R1a and European autosomal DNA is higher around Afghanistan, Tajikistan and northern Pakistan, then decreases progressively towards southern an eastern India.
2) Indo-European conquerors probably took a lot of native wives in the early years, which further diluted the European autosomes while keeping hg R1a high. I expect that the same thing happened with R1b among the Basques.
Some people have advanced the possibility that R1a was already present in India long before the Bronze Age, in Paleolithic times. Phylogenetic studies, though, point at a South Siberian origin of R1a, which I think is too remote from India to support such a hypothesis. Indian R1a lineages show less divergence than those in Central Asia, Russia or the Balkans. Although Indian R1a is quite varied, this kind be better explained by the huge historical population of India. More births create more mutations. This should be considered when calculating the time to the most recent common ancestor. The Indian subcontinent is at least 10 times more numerous than southern Russia and Siberia nowadays, and certainly held an even greater proportions in the past, before modern agricultural techniques, modern transportations and modern housing allowed for higher densities of population in very cold and isolated regions.
The Turks
Here the 7% of Siberia and East Asian haplogroups of probable Turkic origin (C, N, O, Q) corresponds quite well to the 6% of Siberian and East Asian autosomal DNA. Likewise, the roughly 5% of typical South Asian haplogroups (H, L, R2) are not far off the 3.5% of Indian and Dravidian (Irula and North Kannadi) admixture. Both were of course a bit diluted.
This graph shows a clearer picture, with about 3% of South Asian, 4% of Northeast Asian and 2.5% of East Asian.

Turkey is a good example of how an ethnic minority can impose its language on a vast territory (Turkic languages originated in the Altai region of Siberia near Mongolia).
The Iberians
There has long been a controversy (on this forum) about the origin of African haplogroups (E-M81 or mtDNA L) in southern and western Iberia in particular. Autosomal admixture confirm a small but substantial percentage of both Northwest African (5.7%) and East African (1.8%) DNA among the Portuguese. Spaniards have in average 2.2% of Northwest African DNA, 0.6% of East African and 0.2% of West African. The Basques, who have nearly no African Y-DNA or mtDNA, lack completely African autosomes.
Portugal
The Portuguese have in total 7.5% of African autosomal DNA, which matches the percentage of African Y-DNA. According to the Adams et al. study of Iberian Y-DNA, North Portugal has 3% of E1b1b1b (E-M81) and 3% of sub-Saharan African E1. South Portugal has 8% of E-M81 and 1% of E1b1a. This gives an average of exactly 7.5% of African Y-DNA for Portugal.
4.5% of the Portuguese autosomes originated in Southwest Asia (I.e. the Arabian peninsula, Levant and southern Mesopotamia). Haplogroups corresponding to this region are E1b1b1a (E-M78), E1b1b1c (E-M123), J1 and T. To facilitate the breakdown I will consider G2a and J2 as West Asian, and L as South Asian. Still based on Adams et al., the North Portuguese have in total 11% of Southwest Asian haplogroups, against 16% for the South Portuguese. In this case the Y-DNA exceeds the actual autosomal percentage. This is almost certainly because Southwest Asian were already a melting pot of populations, that included some European blood. The Dodecad admixtures show that the Syrians, Jordanians and Egyptians have between 15% and 20% of South European DNA.
The same thing can be observed with West Asian haplogroups (G2a, J2), which make up 19% of lineages in North Portugal and 24% in South Portugal, but only reach 7% of autosomal DNA.
Here are the admixtures of Portuguese Dodecad members.
Spain
The Spanish have 3% of African autosomal DNA, which is roughly equal to the proportion of E-M81.
Spaniards have been much less influenced by the Middle East than Portugal, except for the regions of Extremadura, Andalusia, Murcia and Valencia. In average they carry only 3.3% of Southwest Asian autosomal DNA, and 8.5% of West Asian one. This is more in agreement with Y-DNA (roughly 5% from Southwest Asia and 7% from West Asia) than in Portugal. But it would be interesting to compare Dodecad results region by region.
Analysis
It is not surprising to find a high percentage of Southwest Asian DNA in Portugal and southern Spain considering the importance that the Levant and Arabia played in the local history, starting with the establishment of Neolithic farmers some 8000 years ago, then the Phoenician colonisation, and finally the Arabic conquest of Al-Andalus.
The ratio of northern vs southern European DNA is about half-half for Portugal and 1/3 northern, 2/3 southern for Spain. This supports the theory of a denser Germanic in Portugal than in Spain.
Last edited: