Angela
Elite member
- Messages
- 21,823
- Reaction score
- 12,329
- Points
- 113
- Ethnic group
- Italian
I thought I'd start a general thread for questions about how 23andme works, since people do have general questions about the algorithm and how to interpret results.
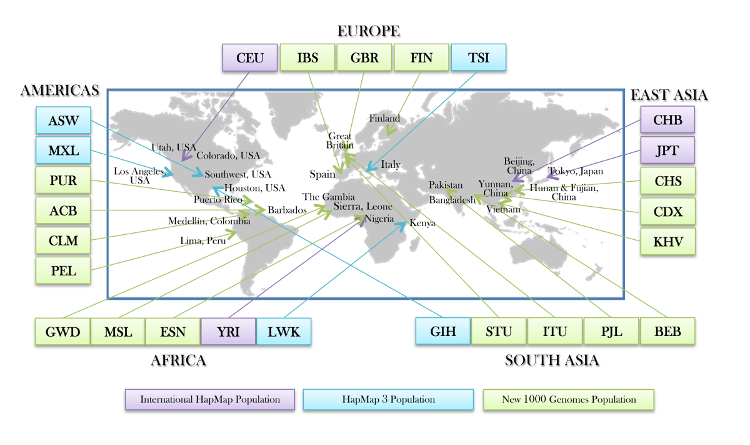
I'll just start with one important point that still causes some confusion. The accuracy of the results is dependent on the coverage in terms of number of samples for any given area.
If person X has all ancestors from region Y for five hundred years, and there were lots and lots of representative samples from region Y, 23andme would be able to tell person X that he or she is 100% typical of that region.
Unfortunately, 23andme doesn't have anywhere near the number of samples from most areas for that to work accurately.
I'll use as an example a sample from La Spezia, Italy, a Ligurian city.
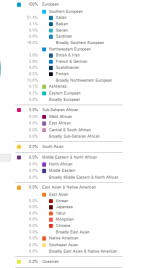
This person's family is documented in the area since the middle 1500s. By any common sense definition, this person is "Italian". Yet, these are the results from 23andme:

Why is the "Italian" score so low? The reason is that there are an infinitesimal number of northern Italians in the 23andme "Italian" reference population. Most of the samples used are from Italian-Americans whose ancestors came from southern Italy and Sicily. The next largest group is from Tuscany, because of the many academic studies done there, including 1000 genomes. This Spezzino, coming from an area close to Toscana, will share alleles with them, and so shows up as more "Italian" than someone from Friuli, for example, who might only score 35% "Italian"
For northern Italians, all they have are the 8 samples from Bergamo and the handful of private testees.
If there were hundreds and hundreds of samples from each area the total for "Italian" would go way up.
This applies even to southern Italians, I think, and their supposed additional "Middle Eastern" (actually Caucasus) percentages. If there are a lot of samples from a given town, the algorithm has more of a chance to recognize the next person to test from that area as having a very high "Italian" percentage. However, that isn't always the case. The total number of Italians who has tested is smaller by a couple of orders of magnitude than the number of people of British descent who have tested, for example. So some people won't match perfectly.
This has application when comparing southern Italians and Greeks as well. As a result of the way that 23andme clusters different groups it obscures more ancient relationships. Every other academic genetic analysis I can recall finds very similar "Caucasus" and "West Asian" in mainland Greeks as in southern Italians, yet that doesn't appear to be the case in 23andme. The genetics hasn't changed; it's just an artifact of the 23andme method.
People lose sight of what service 23andme is trying to provide. It's attempting to tell people where the majority of their ancestors lived in the last 500 years. It isn't, like academic studies, trying to trace the population history of each region over the last 3000 or 5000 years. Even for its stated goal, it isn't producing a totally accurate picture, partly because it doesn't have enough samples from certain areas, and partly because I don't think that's ever been their primary focus, and it's less important to them by the day. If they really cared about this, they'd at least include all the samples from all the academic papers that have been done. They haven't and they won't. No one should even expect an update of AC based on all the new samples they get.
The other problem is that some people attempt to use their results for one agenda driven purpose or another without really understanding how the algorithm works.
This is part of the reason why there's a push back about these consumer ancestry tests. Some companies mislead (which I don't think 23andme has done). In other cases, people just don't understand the limitations of this kind of testing, or are just deliberately misusing the results.
Anyway, that's my two cents.
I'll just start with one important point that still causes some confusion. The accuracy of the results is dependent on the coverage in terms of number of samples for any given area.
If person X has all ancestors from region Y for five hundred years, and there were lots and lots of representative samples from region Y, 23andme would be able to tell person X that he or she is 100% typical of that region.
Unfortunately, 23andme doesn't have anywhere near the number of samples from most areas for that to work accurately.
I'll use as an example a sample from La Spezia, Italy, a Ligurian city.
This person's family is documented in the area since the middle 1500s. By any common sense definition, this person is "Italian". Yet, these are the results from 23andme:
Why is the "Italian" score so low? The reason is that there are an infinitesimal number of northern Italians in the 23andme "Italian" reference population. Most of the samples used are from Italian-Americans whose ancestors came from southern Italy and Sicily. The next largest group is from Tuscany, because of the many academic studies done there, including 1000 genomes. This Spezzino, coming from an area close to Toscana, will share alleles with them, and so shows up as more "Italian" than someone from Friuli, for example, who might only score 35% "Italian"
For northern Italians, all they have are the 8 samples from Bergamo and the handful of private testees.
If there were hundreds and hundreds of samples from each area the total for "Italian" would go way up.
This applies even to southern Italians, I think, and their supposed additional "Middle Eastern" (actually Caucasus) percentages. If there are a lot of samples from a given town, the algorithm has more of a chance to recognize the next person to test from that area as having a very high "Italian" percentage. However, that isn't always the case. The total number of Italians who has tested is smaller by a couple of orders of magnitude than the number of people of British descent who have tested, for example. So some people won't match perfectly.
This has application when comparing southern Italians and Greeks as well. As a result of the way that 23andme clusters different groups it obscures more ancient relationships. Every other academic genetic analysis I can recall finds very similar "Caucasus" and "West Asian" in mainland Greeks as in southern Italians, yet that doesn't appear to be the case in 23andme. The genetics hasn't changed; it's just an artifact of the 23andme method.
People lose sight of what service 23andme is trying to provide. It's attempting to tell people where the majority of their ancestors lived in the last 500 years. It isn't, like academic studies, trying to trace the population history of each region over the last 3000 or 5000 years. Even for its stated goal, it isn't producing a totally accurate picture, partly because it doesn't have enough samples from certain areas, and partly because I don't think that's ever been their primary focus, and it's less important to them by the day. If they really cared about this, they'd at least include all the samples from all the academic papers that have been done. They haven't and they won't. No one should even expect an update of AC based on all the new samples they get.
The other problem is that some people attempt to use their results for one agenda driven purpose or another without really understanding how the algorithm works.
This is part of the reason why there's a push back about these consumer ancestry tests. Some companies mislead (which I don't think 23andme has done). In other cases, people just don't understand the limitations of this kind of testing, or are just deliberately misusing the results.
Anyway, that's my two cents.
Attachments
Last edited: