At least G25 co-ordinates attempt to connect with reality.
What are you talking about?
You are mixing fact and fantasy.
I'd rather you were a troll.
Unfortunately you are worse than that.
You are a fantasist.
No man, I’m not scientifically claiming that the deities existed; they’re just analogies to explain the high degree of endogamy among the Etruscans and all those populations of elitist origin.
Mythologies are overwhelmingly indicative, and only now are we starting to have tools that allow us to reinterpret how much truth they actually contained.
Did the deity Tinia exist?
Yes, on a practical level: for an ethnicity to have a mythological/real origin, it is necessary that all males share the same founder effect and that the rates exceed more than 50% of the male population so as not to fall into genetic drift. Without planned endogamy, PCA samples would keep shifting continuously and there would be no region that could delimit ethnic groups. It’s not that “Tinia” literally existed in 2600 BC; rather, a direct descendant of him who consolidated himself as king around 900 BC deified him, because they knew perfectly well that they descended from an uninterrupted foundational lineage lasting millennia.
What cannot be stated is whether “Tinia” was an L2, a Z36, or a Z56.
Those are anachronisms to try to uncover events that happened before writing.
On what date does the “endogamic knot” of all Italian U152* fall?
In 2600–2400 BC, not in 2200–2000 BC. In 400 years, “Tinia” filled central and northern Italy with U152* offspring. There were no massive migrations from anywhere, neither Steppe nor Central European — it was internal expansion. The intrusion of Celts beyond the Alps, Iberians, or Illyrians was at most around 5% and random.
Does that mean that “Tinia” was the father of all U152?
That would be an exaggeration; he would only be the father of about 60% of all U152.
Let’s take a hypothetical example where there is a version of an autosomal SNP related to the heart, common in 80% of U152, called HF257.
If 90% of Tinia’s children have HF257-23 and you find that same mutation in an Australian from 1600 BC, by brute statistical force an Etruscan years earlier must have taken a boat and ended up in Australia, and it cannot be the result of a Germanic Celtic arrival because U152>L2>Z49 have HF257-65.
That’s how autosomal calculators theoretically work with thousands of similar preselected mutations, but the errors come from missing spatiotemporal pieces: two months later it turns out that HF257-23 is also detected in a Gallic population, and in the end that mutation was not original to “Tinia” but to the inbred Gallic cousin of Tinia’s son who had the most children.
As a result, HF257-23 reached Australia through a Gallic cousin who intermarried with Tinia’s line, but it did not arrive directly through any male lineage.
That’s why this kind of migrational reasoning can only be done with Y chromosome SNPs and STRs.
Not with poorly calibrated autosomal mixtures.
It’s because of this kind of bullshit that my fellow Spaniards make a one-hour documentary about Columbus’s DNA and have the sheer nerve not to even mention the Y lineage, because they are basing it on SCHIZOPHRENIA.
That’s why calculators fed with 10,000 ancient DNA samples can change radically by adding another 100 or even just one single ancient sample. What really clarifies the “paths” is Y phylogeny.
All this about “deities” are lines of reasoning we would never have believed possible years ago. The endogamy practiced by all M269> groups, especially P312>, is absolutely brutal.
Back around 2016, when people said there was a very strong founder effect around 3000 BC, I firmly claimed (among biologist colleagues) that this would eventually resolve into many bottlenecks going back to 10,000 BC or earlier.
The “many” part was true, but almost all the knots are between 2800–2400 BC. That is not normal at all.
More than 10 years ago people talked about Genghis Khan causing a founder effect of over 10 million descendants, which seemed insane. Today we know we can’t be sure it was Genghis Khan himself, but it was done by someone of his ethnicity.
There are thousands of Y-SNP clades with several million descendants, but having more than 50 million within just 5,000 years is totally disproportionate.
P312> can easily exceed 200 million. R1a-Z94 I’ve never estimated, but rough calculation also puts it near 200 million.
These are absurd numbers that far exceed any fantasized deity.
We’re not talking about supernatural fantasy, just genealogy distorted by fanatic religious cults and isolation.
The statistical norm of having 6 U152 great-great-grandfathers in the Iron Age among Etruscans no longer exists; that population is extinct today. The closest thing are populations that patrilineally descend from them in the same area and still have 3 or 4 U152 great-great-grandfathers today.
Basques in the Iron Age had on average 7 out of 8 great-great-grandfathers as P312>, and today they still have 7 out of 8 grandfathers as P312, and are therefore the ethnicity with the greatest continuity of total SNPs. They haven’t shifted in PCA in more than 4,000 years, whereas all Italic populations did after Rome. Basques are the strangest ethnicity on the planet.
So this isn’t bullshit or fantasy — it’s extreme endogamy. Only in the Iron Age could you systematically find genetic profiles with extreme homozygosity, especially in male lineages.
According to your profile, Vallicanus, you are U152 and show a very high match with the Picenes.
But you are not an inbred Iron Age Picene, right?
The matches those calculators give are preselected SNPs, so it comes out the same whether both ancient and modern samples have 5% or 40% coverage.
Because what they measure are SNPs resulting from extremely, extremely endogamic knots.
Mythological deities are simply genealogical distortions that really did exist; those degrees of endogamy don’t arise or persist by themselves.
What we don’t really know is which specific SNP was which deity, but any SNP that consolidated more than 10 different branches within 100 years, whether we like it or not, deserves the title of “deity”.
Foundational branches are not about sleeping with everyone, having 100 children and letting chance do its thing.
Foundational branches are about having 20 children and educating them so that they also have 20 children, so that in the future 10 branches consolidate.
There is the case of a guy called Jonathan Jacob Meijer who illegally donated sperm and today has more than 1,000 children.
Will that guy have a foundational SNP 200 years later?
NO. He’s a nutcase, and the women who resort to anonymous fertilization aren’t exactly mentally stable either (and they got fertilized by a nutcase). Those kids won’t know their biological father and in three generations most will be extinct, or there will be fewer than 1,000 people with that Y-SNP. If “Tinia” had done it, in 200 years there would be 30,000.
Immediate SNP branches do not represent sons, they represent consolidated descendants.
I’ve often read the claim that the Y chromosome only contributes 2% of the genome.
What happens if there is an SNP like P312 with a pedigree collapse of a number followed by 60 zeros, when a million only has 6 zeros?
The result is that P312 easily contributed more than 40% of all autosomes in Western Europe.
In summary:
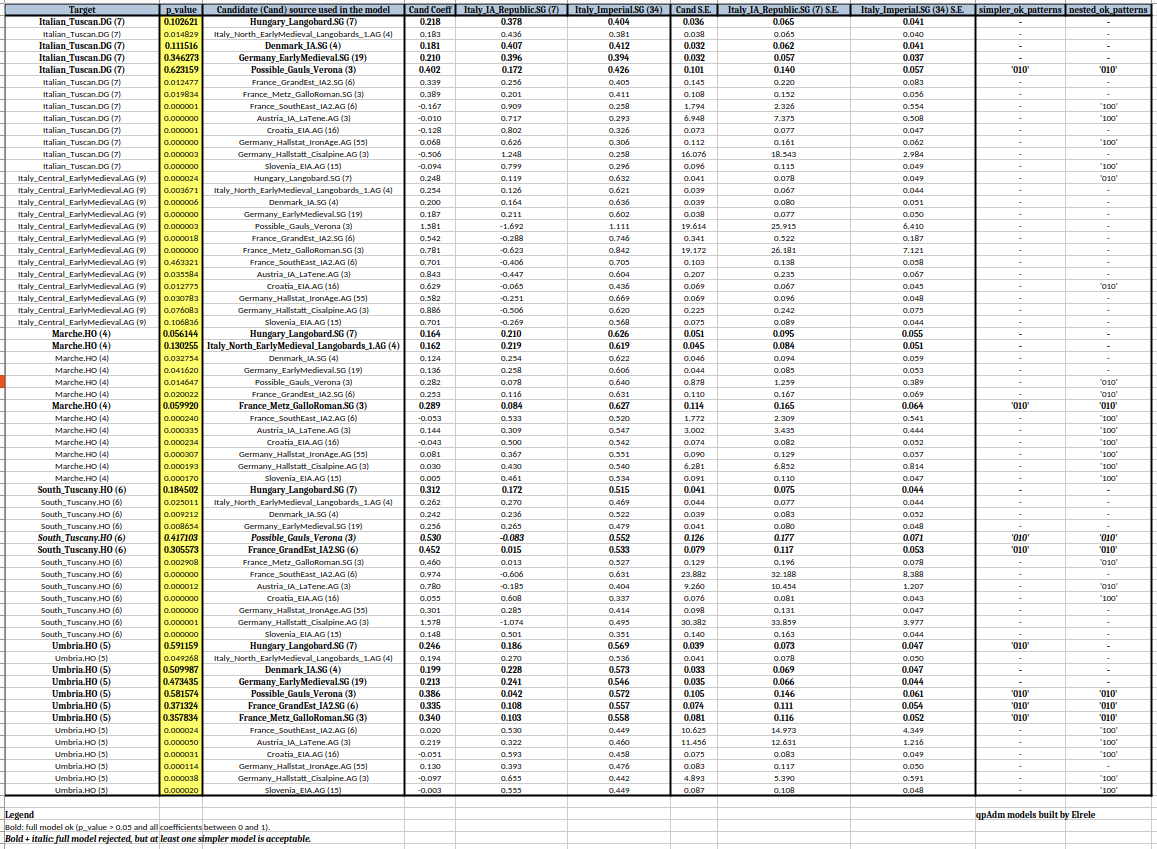
People who claim you can model a central Italian as 80% Etruscan samples, 12.5% Bronze Age Germanic, and 7.5% Levantine Canaanite…
1 have a strong ideological bias.
2 suffer from biological illiteracy.
3 or a mix of both.
The 12.5% “Germanic” is actually P312> clades (proto-Celts) expanding from south to north between 2600–2200 with the Bell Beakers, and the 7.5% Levantine “Canaanite” belongs to Aegeans (G2, J1, J2, T, E, R1B) who invaded the Levant with the Sea Peoples (Mycenaeans – Proto-Phoenicians).
Models with acceptable results can be obtained in either direction because autosomes don’t tell you the order — only phylogeny does.