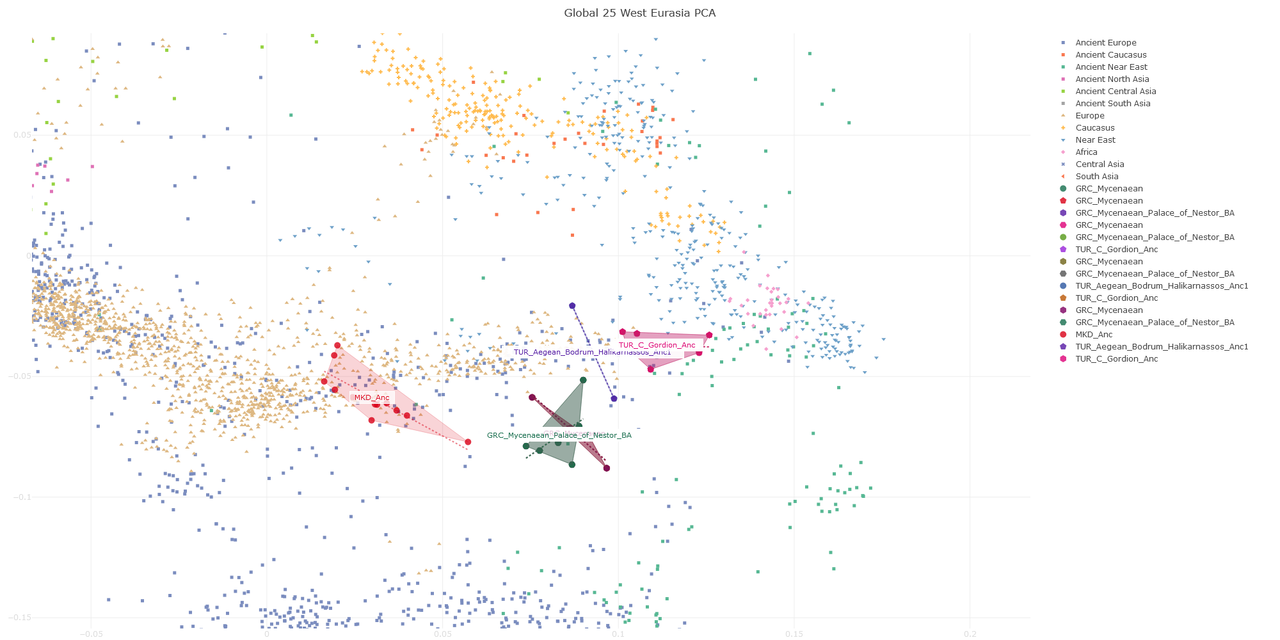
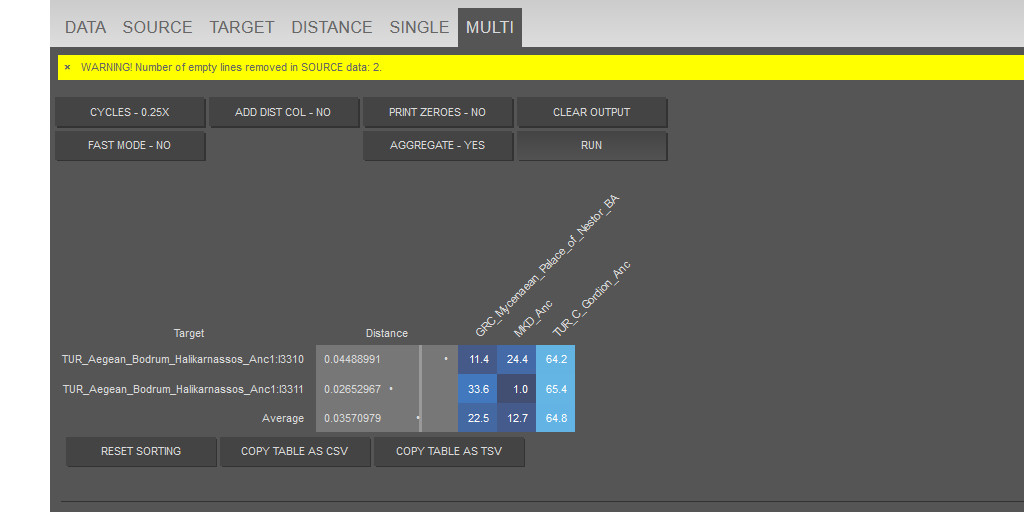
TUR_Aegean_Mugla_Degirmendere_Anc:I20224,0.122929,0.160454,-0.031678,-0.070414,0.000615,-0.018686,-0.00047,-0.011076,-0.001023,0.028976,0.001461,0.004796,-0.019772,-0.005367,-0.017372,-0.00053,0.011995,0.00076,0.003645,-0.01063,-0.005865,0.00643,-0.009367,-0.001205,-0.002994TUR_Aegean_Mugla_Degirmendere_Anc:I20225,0.117238,0.15436,-0.033941,-0.075905,0.001231,-0.026216,0.00705,-0.006,0.001227,0.031162,0.007957,0.006145,-0.021556,-0.007569,-0.013572,0.011933,0.031683,-0.003294,0.004399,-0.00075,-0.000873,0.00507,-0.007395,0.000843,0.005149
TUR_Aegean_Mugla_Degirmendere_Anc:I20226,0.10927,0.160454,-0.024513,-0.070737,0.00277,-0.027889,0,-0.002077,-0.008999,0.035172,0.001299,0.011989,-0.015907,0.007844,-0.016286,0.001326,0.018384,-0.004814,0.00993,-0.006753,-0.009109,0.003215,0.007025,-0.001566,-0.006227
TUR_Aegean_Mugla_Degirmendere_Anc:I20227,0.10927,0.152329,-0.031301,-0.069122,0.006463,-0.034025,0.00141,-0.004615,-0.011044,0.028611,-0.00065,0.004946,-0.009068,-0.003303,-0.018865,0.009281,0.026077,-0.005068,0.008045,-0.011881,-0.01148,0.000618,0.003204,0.003374,0.002155
TUR_Aegean_Mugla_Degirmendere_Anc:I20228,0.108132,0.153345,-0.040729,-0.063954,0.010463,-0.022032,0.000705,-0.002769,-0.002863,0.025513,-0.002598,0.002698,-0.015312,-0.000688,-0.014251,0.003315,0.015646,0.006208,0.014581,-0.002751,-0.006489,0.003586,-0.000123,0.002771,0.002515
TUR_Aegean_Mugla_Degirmendere_Anc:I20229,0.111547,0.157407,-0.029793,-0.069445,0.000615,-0.02008,-0.000705,-0.013153,-0.006954,0.037358,-0.000487,0.008692,-0.016353,0.007019,-0.023344,-0.005967,0.011604,0.007855,0.002765,-0.003502,-0.007736,0.000618,0.005053,-0.001566,-0.000239
TUR_Aegean_Mugla_Degirmendere_Anc:I20230,0.103579,0.158423,-0.027907,-0.062985,0.011387,-0.024263,0.003055,-0.008307,-0.010022,0.034443,0.002598,0.014237,-0.017245,-0.007569,-0.020087,0.004906,0.032596,-0.00228,0.005531,-0.001376,-0.003993,0.001855,-0.00037,-0.000723,0.00491
TUR_Aegean_Mugla_Degirmendere_Anc:I20231,0.1161,0.161469,-0.038843,-0.075905,0.003077,-0.025379,0.00047,-0.006923,-0.010226,0.029887,0.001137,0.007044,-0.016204,0.00289,-0.019815,0.001458,0.01004,0.005701,0.010307,-0.002751,-0.00574,0.004822,-0.003451,-0.004217,-0.012693
TUR_Aegean_Mugla_Degirmendere_Anc:I20232,0.112685,0.165531,-0.031301,-0.076228,0.010463,-0.033746,0.00799,-0.004846,0.000205,0.034625,0.007795,0.007044,-0.01888,-0.004266,-0.016829,0.002254,0.025555,0.00266,0.007542,0.001126,-0.00262,-0.000866,0,0.004338,-0.001916
TUR_Aegean_Mugla_Degirmendere_Anc:I20233,0.112685,0.156392,-0.027153,-0.0646,0.003385,-0.023427,0.000705,-0.009461,0.003886,0.033714,0.00406,0.006894,-0.013677,-0.007019,-0.023072,0.008353,0.027902,-0.004307,-0.001634,-0.004752,-0.005116,0.001113,0.005053,0.003133,-0.001916
TUR_Aegean_Mugla_Degirmendere_Anc:I20257,0.113823,0.160454,-0.024513,-0.072998,0.011079,-0.027889,-0.00658,-0.002538,-0.007158,0.035718,0.000325,0.008542,-0.015609,-0.003578,-0.016965,0.001193,0.017471,0.003674,0.006536,-0.002126,-0.011729,0.005564,-0.003081,-0.00253,0.000599
TUR_Aegean_Mugla_Degirmendere_Anc:I20258,0.10927,0.161469,-0.031678,-0.070091,0.00277,-0.027052,0.003995,-0.007846,-0.009817,0.036265,0.007795,0.011839,-0.016055,0.003165,-0.009093,-0.005436,0.013299,0.004054,0.003645,-0.001251,-0.004617,0.01014,-0.006409,0.004699,-0.001197