-
Don't want to see ads? Install an adblocker like uBlock Origin or use a Europe-based privacy-friendly browser like Vivaldi or Mullvad.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Genetic affinities between an ancient Greek colony and its metropolis: the case of 2 Amvrakia in western Greece
- Thread starter lockdownboredom
- Start date
PaleoRevenge
Well-known member
- Messages
- 1,529
- Reaction score
- 1,344
- Points
- 113
Have you run any models on these bardhoc samples?
Yes, I've posted them, if you search my history you'll eventually find various models, I posted them as images. The Bardhoc samples can be modeled as Bulgaria Roman(a single E-V13 sample) + Slavic. They barely pass as one way model with Doclea - Roman sample(J2b from Montenegro). They can also be modeled with I18832(E-V13 from late Iron Age Hungary).
They are good proxy for early Albanian. The Sicilian mdv E-V13 samples from the Norman period can almost be modeled as Bardhoc + Norman/Anglo-Saxon.
Thucydides enjoyer
Regular Member
- Messages
- 47
- Reaction score
- 29
- Points
- 18
It isnt that bad when i have post iron age proxies as a source.I am also interested in running my results with qpAdm,although i have some difficulties in converting my raw file to EIGENSTRAT format.Although,i think that G25 gives me an idea of my ancestry with some accuracy.Many people on X can demonstrate there's a big inflation of "Natufian" in G25. Frankly, you should just wait till the samples are in v63.0 of AADR. G25 is built on fixed synthetic components, while formal tools like qpAdm actually examine polymorphic SNPs to make determinations on how to accurately model populations. Moreover, there aren't any metrics in G25 to determine if a model is actually statistically robust.
G25 is basically astrology, while formal tools found in the Admixtools2 suite are the legitimate means of analyzing aDNA.
In private DM, I've spoken to top researchers and they are completely aloof to what g25 is. This demonstrates how inconsequential it is to the experts in the field.
Thucydides enjoyer
Regular Member
- Messages
- 47
- Reaction score
- 29
- Points
- 18
Isnt there an illyrian component?Yes, I've posted them, if you search my history you'll eventually find various models, I posted them as images. The Bardhoc samples can be modeled as Bulgaria Roman(a single E-V13 sample) + Slavic. They barely pass as one way model with Doclea - Roman sample(J2b from Montenegro). They can also be modeled with I18832(E-V13 from late Iron Age Hungary).
They are good proxy for early Albanian. The Sicilian mdv E-V13 samples from the Norman period can almost be modeled as Bardhoc + Norman/Anglo-Saxon.
PaleoRevenge
Well-known member
- Messages
- 1,529
- Reaction score
- 1,344
- Points
- 113
Isnt there an illyrian component?
Illyrian component is a minor component, it is likely in terms of admixture less than Slavic component in Albanian. This is not the right topic to continue this discussion, a while back I ran many models and posted a good chunk on this thread:
"Ancient DNA reveals the origins of the Albanians"
Big new paper. Think it should have a dedicated thread.
LINK:
https://www.biorxiv.org/content/10.1101/2023.06.05.543790v1
Conclusions:
"However, in agreement with linguistic studies, we find that Albanians likely descend from a surviving West palaeo-Balkan population that experienced significant demographic increase approximately between 500-800 CE, perhaps after a population bottleneck. We show that in contrast to the rest of the Balkans, the Medieval samples from both North and South Albania experienced little to no...
Big new paper. Think it should have a dedicated thread.
LINK:
https://www.biorxiv.org/content/10.1101/2023.06.05.543790v1
Conclusions:
"However, in agreement with linguistic studies, we find that Albanians likely descend from a surviving West palaeo-Balkan population that experienced significant demographic increase approximately between 500-800 CE, perhaps after a population bottleneck. We show that in contrast to the rest of the Balkans, the Medieval samples from both North and South Albania experienced little to no...
- Johane Derite
- Replies: 245
- Forum: Paleogenetics

Albanian most prominent haplogroup E-V13 has no connection with Illyrians. And I am confident R-Z2705 will be proven the same, once more ancient samples become public, these two are the core Albanian y-haplogroups.
And the linguistic argument is well known, the Illyrian hypothesis is a forced argument with lots of oversights. I've presenting new evidence in favor for a Daco-Thracian origin(still ongoing):
This is a thread mainly centered on the Hutsul dialect of the Carpathian mountains. The Hutsul speak a Slavic dialect, but a very unique Slavic dialect. In it are hundreds of non-Slavic words that have clear cognates to Albanian. The vast majority of these words are unique to the Hutsul dialect, some have acquired a pan Carpathian character and radiate to the neighboring dialects. Some have even entered formally the Ukrainian language. This work represents almost six months of research, the lexicons that will be presented are so unique that the majority of them are only shared between...
- PaleoRevenge
- albanian albanian language albanians beskids beskydy carpi dacia dacian language dacians e-v13 gorals hutsuls hutuli lemkos romanian substrate thrace thracian language thracians vladimir i. georgiev
- Replies: 230
- Forum: Linguistics


And you can read all the back and forth debates in the main thread:
Saw this video, found it to be a good intro to some basics.
- Johane Derite
- Replies: 4,649
- Forum: Linguistics
Jovialis
Advisor
- Messages
- 9,901
- Reaction score
- 6,809
- Points
- 113
- Ethnic group
- Italian
- Y-DNA haplogroup
- R1b-PF7566>Y227216
- mtDNA haplogroup
- H6a1b7
Here is the full pipeline, you can get Grok or Chatgpt to help tailor the coding to your needs. If you get your hands on your FASTQ files, it would be optimal.It isnt that bad when i have post iron age proxies as a source.I am also interested in running my results with qpAdm,although i have some difficulties in converting my raw file to EIGENSTRAT format.Although,i think that G25 gives me an idea of my ancestry with some accuracy.
Code:
I used this pipeline, it processes raw genomic data from paired-end FASTQ files to generate merged genotype data compatible with the AADR (Allen Ancient DNA Resource) dataset, enabling population genetics analysis. It is specifically prioritized to handle a modern FASTQ for merging with AADR. It begins by setting up a working environment and installing essential tools like samtools, bwa, fastp, Picard, pileupCaller, and EIGENSOFT. The pipeline then downloads and prepares the GRCh37 reference genome (with decoy sequences), adjusts its FASTA headers, and indexes it for alignment. Paired-end FASTQ files are trimmed and filtered using fastp, aligned to the reference with bwa mem, and converted to sorted, indexed BAM files with samtools. Duplicates are removed using Picard, and the resulting BAM is processed with pileupCaller to extract genotypes at 1240k SNP positions from the AADR dataset, producing EIGENSTRAT files. Finally, the pipeline merges the sample’s genotype data with the AADR dataset using mergeit, creating a unified dataset for downstream analysis, with verification steps throughout to ensure data integrity:
# Set Your Working Directory
WORKDIR="<WORKDIR>"
cd "$WORKDIR" || { echo "Error: Unable to change directory to $WORKDIR"; exit 1; }
# 1. Update Packages and Install Required Tools
sudo apt-get update && sudo apt-get install -y samtools bwa wget gzip fastp parallel
# Install Picard manually
wget https://github.com/broadinstitute/picard/releases/download/3.2.0/picard.jar -O <OUTPUT_DIR>/picard.jar
# Install pileupCaller (sequenceTools)
wget https://github.com/stschiff/sequenceTools/archive/refs/tags/v1.6.0.tar.gz
tar -xzf v1.6.0.tar.gz
cd sequenceTools-1.6.0
make
sudo cp pileupCaller /usr/local/bin/
cd "$WORKDIR"
# Install EIGENSOFT (for mergeit)
wget https://github.com/DReichLab/EIG/archive/refs/tags/v8.0.0.tar.gz
tar -xzf v8.0.0.tar.gz
cd EIG-8.0.0/src
make
sudo cp mergeit /usr/local/bin/
cd "$WORKDIR"
# 2. Download the Reference Genome
wget ftp://ftp.1000genomes.ebi.ac.uk/vol1/ftp/technical/reference/phase2_reference_assembly_sequence/hs37d5.fa.gz -P <OUTPUT_DIR>/
# 3. Verify the Download
ls -lh <OUTPUT_DIR>/hs37d5.fa.gz
# 4. Decompress the FASTA File
gunzip <OUTPUT_DIR>/hs37d5.fa.gz
# 5. Inspect FASTA Headers
grep "^>" <OUTPUT_DIR>/hs37d5.fa | head -n 20
# 6. Adjust FASTA Headers
sed -E 's/^(>[^ ]+).*/\1/' <OUTPUT_DIR>/hs37d5.fa > <OUTPUT_DIR>/hs37d5.adjusted.fa
# 7. Verify Adjusted Headers
grep "^>" <OUTPUT_DIR>/hs37d5.adjusted.fa | head -n 20
# 8. Index the Adjusted FASTA with samtools
samtools faidx <OUTPUT_DIR>/hs37d5.adjusted.fa
# 9. Index the Adjusted FASTA with bwa
bwa index <OUTPUT_DIR>/hs37d5.adjusted.fa
# 10. Trim Paired-End FASTQ Files with fastp
fastp \
-i <INPUT_DIR>/<SAMPLE_NAME>_1.fq.gz \
-I <INPUT_DIR>/<SAMPLE_NAME>_2.fq.gz \
-o <OUTPUT_DIR>/<SAMPLE_NAME>_1.trim.fq.gz \
-O <OUTPUT_DIR>/<SAMPLE_NAME>_2.trim.fq.gz \
-q 20 \
-u 30 \
--detect_adapter_for_pe \
-h <OUTPUT_DIR>/fastp_report.html \
-j <OUTPUT_DIR>/fastp_report.json
# 11. Align Trimmed FASTQ Files to Reference and Convert to BAM
bwa mem -M <OUTPUT_DIR>/hs37d5.adjusted.fa \
<OUTPUT_DIR>/<SAMPLE_NAME>_1.trim.fq.gz \
<OUTPUT_DIR>/<SAMPLE_NAME>_2.trim.fq.gz | \
samtools view -bS - > <OUTPUT_DIR>/<SAMPLE_NAME>.raw.bam
# 12. Sort the Raw BAM File
samtools sort -o <OUTPUT_DIR>/<SAMPLE_NAME>.sorted.bam \
<OUTPUT_DIR>/<SAMPLE_NAME>.raw.bam
# 13. Index the Sorted BAM File
samtools index <OUTPUT_DIR>/<SAMPLE_NAME>.sorted.bam
# 14. Generate Alignment Statistics
samtools flagstat <OUTPUT_DIR>/<SAMPLE_NAME>.sorted.bam
# 15. Mark and Remove Duplicates with Picard
java -jar <OUTPUT_DIR>/picard.jar MarkDuplicates \
I=<OUTPUT_DIR>/<SAMPLE_NAME>.sorted.bam \
O=<OUTPUT_DIR>/<SAMPLE_NAME>.dedup.bam \
M=<OUTPUT_DIR>/<SAMPLE_NAME>.dup_metrics.txt \
REMOVE_DUPLICATES=true
samtools index <OUTPUT_DIR>/<SAMPLE_NAME>.dedup.bam
# 16. Verify the Deduplicated BAM
samtools view -H <OUTPUT_DIR>/<SAMPLE_NAME>.dedup.bam | head
# 17. Obtain AADR Dataset (Manual Step)
# Download <AADR_VERSION>.{geno,snp,ind} manually and place in <AADR_DIR>/
# Verify
ls -lh <AADR_DIR>/<AADR_VERSION>.*
# 18. Create BED File for Targeted Positions
awk '{print $2 "\t" ($4-1) "\t" $4}' <AADR_DIR>/<AADR_VERSION>.snp > <OUTPUT_DIR>/AADR_positions.bed
head <OUTPUT_DIR>/AADR_positions.bed
# 19. Generate EIGENSTRAT Files
samtools mpileup -B -q30 -Q30 -f <OUTPUT_DIR>/hs37d5.adjusted.fa \
-l <OUTPUT_DIR>/AADR_positions.bed \
<OUTPUT_DIR>/<SAMPLE_NAME>.dedup.bam | \
pileupCaller --randomHaploid --sampleNames <SAMPLE_NAME> --eigenstratOut <SAMPLE_NAME> \
--snpFile <AADR_DIR>/<AADR_VERSION>.snp
# 20. Fix .ind File for Sample
echo "<SAMPLE_NAME> <SEX> <POPULATION>" > <WORKDIR>/<SAMPLE_NAME>.ind
cat <WORKDIR>/<SAMPLE_NAME>.ind
# 21. Fix AADR .ind File
awk 'NF==2 {print $0 "\tUnknown"} NF==3 {print $0}' <AADR_DIR>/<AADR_VERSION>.ind > temp.ind && mv temp.ind <AADR_DIR>/<AADR_VERSION>.ind
grep "<SAMPLE_CHECK>" <AADR_DIR>/<AADR_VERSION>.ind
# 22. Create Merge Parameter File
cat << EOF > <WORKDIR>/merge.par
geno1: <AADR_DIR>/<AADR_VERSION>.geno
snp1: <AADR_DIR>/<AADR_VERSION>.snp
ind1: <AADR_DIR>/<AADR_VERSION>.ind
geno2: <WORKDIR>/<SAMPLE_NAME>.geno
snp2: <WORKDIR>/<SAMPLE_NAME>.snp
ind2: <WORKDIR>/<SAMPLE_NAME>.ind
genooutfilename: <WORKDIR>/merged_output.geno
snpoutfilename: <WORKDIR>/merged_output.snp
indoutfilename: <WORKDIR>/merged_output.ind
strandcheck: NO
EOF
# 23. Run the Merge
mergeit -p <WORKDIR>/merge.par
# 24. Verify Merged Files
ls -lh <WORKDIR>/merged_output.*
grep "<SAMPLE_NAME>" <WORKDIR>/merged_output.indVitruvius
Well-known member
- Messages
- 647
- Reaction score
- 1,201
- Points
- 91
- Ethnic group
- Italian
- Y-DNA haplogroup
- I1
- mtDNA haplogroup
- H5a1
What are your thoughts on K36?Many people on X can demonstrate there's a big inflation of "Natufian" in G25. Frankly, you should just wait till the samples are in v63.0 of AADR. G25 is built on fixed synthetic components, while formal tools like qpAdm actually examine polymorphic SNPs to make determinations on how to accurately model populations. Moreover, there aren't any metrics in G25 to determine if a model is actually statistically robust.
G25 is basically astrology, while formal tools found in the Admixtools2 suite are the legitimate means of analyzing aDNA.
In private DM, I've spoken to top researchers and they are completely aloof to what g25 is. This demonstrates how inconsequential it is to the experts in the field.
Vitruvius
Well-known member
- Messages
- 647
- Reaction score
- 1,201
- Points
- 91
- Ethnic group
- Italian
- Y-DNA haplogroup
- I1
- mtDNA haplogroup
- H5a1
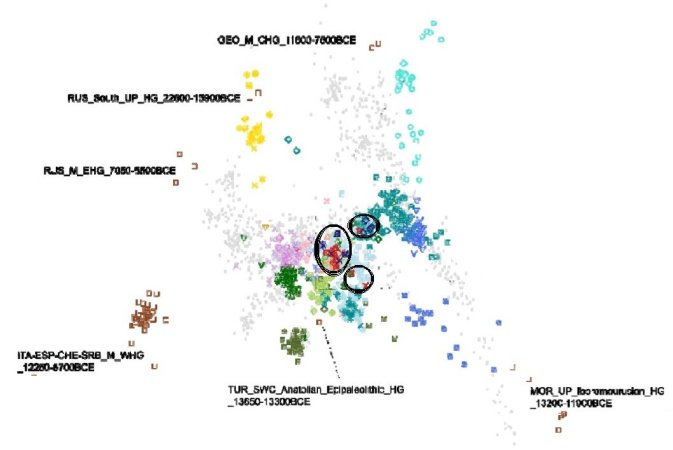
I fit the standard W. Eurasian/N. African PCA overtop of that of the study. The S. Italian/Sicilian/Maltese samples fit neatly into the Greece proper Hellenistic cluster. To differentiate a bit further, it looks like the Sicilian/S. Italian samples bias a hair towards the edge of the Greek Hellenistic cluster pointing to the W. Anatolian/Greek proper Roman-era cluster. I would opine that this might indicate a small influx of Imperial era Greeks into southern Italy overtop of a much larger Greek genetic base that was already established in Italy prior to the conclusion of the pyrrhic wars in ~268BC.
It's clear they actually used the same exact reference PCA/populations as the model I fit when you look closely.
Last edited:
bigsnake49
Regular Member
- Messages
- 1,880
- Reaction score
- 471
- Points
- 83
- Ethnic group
- Thracian
- Y-DNA haplogroup
- R-PF7558 (LDNA)
- mtDNA haplogroup
- U5a1b1d1 (LDNA)
I think the inflow from Western Anatolia started much earlier than the Hellenistic period. I would say around the middle of the 6th century BC (~550BC). I would expect that at that time it was concentrated in the major Greek cities like Athens and Corinth and Thebes. It was a stronger flow later on. Let's wait for those samples .
.
.
Last edited:
Vitruvius
Well-known member
- Messages
- 647
- Reaction score
- 1,201
- Points
- 91
- Ethnic group
- Italian
- Y-DNA haplogroup
- I1
- mtDNA haplogroup
- H5a1
Western Anatolian influx into Greece started in the neolithic and did not end until the Roman era - complete with an immediate arrival of Anatolia's sudden and large Chalcolithic era increase in Caucasian (Armenian/Proto-Armenian) related input. Despite being highly culturally dominant, Greece - particularly at least the peloponese and islands - seem to be areas which was under constant and steady genetic turnover from input stemming from Western Anatolia for an unbroken span of roughly 7000 years. As we can see, by the end of it in the Roman era there is virtually no difference between the W. Anatolian autosomal structure and that of the Tenea samples in mainland Greece.I think the inflow from Western Anatolia started much earlier than the Hellenistic period. I would say around the middle of the 6th century BC (~550BC). I would expect that at that time it was concentrated in the major Greek cities like Athens and Corinth and Thebes. It was a stronger flow later on. Let's wait for those samples
Vallicanus
Regular Member
- Messages
- 1,523
- Reaction score
- 851
- Points
- 113
- Ethnic group
- Italian
- Y-DNA haplogroup
- R1b Z36
So you believe the Caucasus-related element was Armenian-like. How much do you think modern Italians, north, centre, south, islands, owe to this group?Western Anatolian influx into Greece started in the neolithic and did not end until the Roman era - complete with an immediate arrival of Anatolia's sudden and large Chalcolithic era increase in Caucasian (Armenian/Proto-Armenian) related input. Despite being highly culturally dominant, Greece - particularly at least the peloponese and islands - seem to be areas which was under constant and steady genetic turnover from input stemming from Western Anatolia for an unbroken span of roughly 7000 years. As we can see, by the end of it in the Roman era there is virtually no difference between the W. Anatolian autosomal structure and that of the Tenea samples in mainland Greece.
Vitruvius
Well-known member
- Messages
- 647
- Reaction score
- 1,201
- Points
- 91
- Ethnic group
- Italian
- Y-DNA haplogroup
- I1
- mtDNA haplogroup
- H5a1
It's quite significant. One mistake I see a lot of people make is using CHG as a proxy for Caucasian input into southern Europeans when ancestry from neolithic Armenia/Azerbaijan had already absorbed a large sum of anatolian influence and was no longer the same or really similar to Satsurblia HGs.So you believe the Caucasus-related element was Armenian-like. How much do you think modern Italians, north, centre, south, islands, owe to this group?
If we use sources of N. Russia/Ukraine, N. Iran, N. Levant, PPN Iraq, N. Anatolia, N. Armenia/Azerbaijan and EN. Morocco we get proto armenian input quantified at 40-50% in southern Italians, 30-40% in central Italians, and 18-30% in northern Italians.
Vallicanus
Regular Member
- Messages
- 1,523
- Reaction score
- 851
- Points
- 113
- Ethnic group
- Italian
- Y-DNA haplogroup
- R1b Z36
Was Magna Graecian internal migration in Roman Italy the main vector of this Armenian-like element in the Centre and South of Italy while influxes through the Balkans accounted for this element in Northern Italy?It's quite significant. One mistake I see a lot of people make is using CHG as a proxy for Caucasian input into southern Europeans when ancestry from neolithic Armenia/Azerbaijan had already absorbed a large sum of anatolian influence and was no longer the same or really similar to Satsurblia HGs.
If we use sources of N. Russia/Ukraine, N. Iran, N. Levant, PPN Iraq, N. Anatolia, N. Armenia/Azerbaijan and EN. Morocco we get proto armenian input quantified at 40-50% in southern Italians, 30-40% in central Italians, and 18-30% in northern Italians.
Vitruvius
Well-known member
- Messages
- 647
- Reaction score
- 1,201
- Points
- 91
- Ethnic group
- Italian
- Y-DNA haplogroup
- I1
- mtDNA haplogroup
- H5a1
I would say so, yes. In the case of Northern Italy a good amount of the Caucasian ancestry will likely have a bronze age Yamnaya-like origin stemming from Balkanic/carpathian migrations rather than anatolian, but since this is a neolithic model, BA Yamnaya ancestry isn't really accounted for directly. I would guess BA croatia or BA slovenia would function as a decent proxy for what was incoming to Po Valley in the LBA. This will be different than corded ware ancestry which has a lower caucasian affinity and is more widespread in northern europe.Was Magna Graecian internal migration in Roman Italy the main vector of this Armenian-like element in the Centre and South of Italy while influxes through the Balkans accounted for this element in Northern Italy?
The case of central Italy will ultimately be a mix of the two, where as southern Italy will be mostly Magna Graecian derived.
Dianatomia
Regular Member
- Messages
- 436
- Reaction score
- 174
- Points
- 43
- Ethnic group
- Greek
- Y-DNA haplogroup
- J2a
I think this research shows that the Greeks from the LBA and Iron Age started to deviate from Lazarides’ Mycenaean Greeks. Mainland South Greeks seem to be the closest to the Classical Greeks and mainland North Greeks (Epirus, Thessaly, Macedonia) seem to be the closest to Classical and Hellenistic North Greeks. There is continuation compared to the Mycenaean Age, but there is also internal mobility in mainland Greece. Post BA Greeks certainly have more Balkan ancestry. An ancestral dimension which is mostly absent in South Italians during that time. There is also some additional steppe ancestry compared to Mycenaean Greeks.
Also, I would suspect that the Anatolian element would increase in the Aegean side first. Such as Athens, Thebes, the Eastern islands, or rather the Athenian empire. On the other hand Corinth and Amvrasia were part of the Peloponnesian league. They avoided the Anatolian influx. This league however broke 50 years before the Macedonian empire arose. And so during the Hellenistic era Greece became more cosmopolitan in a way. The Anatolian element reached other parts of Greece as well. And after that, it gradually spread to Rome.
So as far as the increase of the Anatolian element is concerned; it starts in Asia Minor (Ionia)) —>Athenian Empire—>Hellenistic Greece —> Rome
Also, Central and North Greece seem to have more Balkanic elements. These elements also start spreading throughout Greece starting the IA.
And so the puzzle continues
Also, I would suspect that the Anatolian element would increase in the Aegean side first. Such as Athens, Thebes, the Eastern islands, or rather the Athenian empire. On the other hand Corinth and Amvrasia were part of the Peloponnesian league. They avoided the Anatolian influx. This league however broke 50 years before the Macedonian empire arose. And so during the Hellenistic era Greece became more cosmopolitan in a way. The Anatolian element reached other parts of Greece as well. And after that, it gradually spread to Rome.
So as far as the increase of the Anatolian element is concerned; it starts in Asia Minor (Ionia)) —>Athenian Empire—>Hellenistic Greece —> Rome
Also, Central and North Greece seem to have more Balkanic elements. These elements also start spreading throughout Greece starting the IA.
And so the puzzle continues
Last edited:
arxaiogenetiki.blogspot
Regular Member
There's no levantine ancestry (or movement in general) into Greece or Italy or any part of Europe. Some levantine-like ancestry might pop up due to a combination of sources used and the BA or/and IA Anatolian ancestry (which itself is 50% Mycenaean as confirmed by Lazaridis) that is indeed detected.I see no indication whatsoever of any levantine pull of ancestry or levantine outliers for the Greek samples. This highlights more than anything the continuation of the bronze age pattern of Greece continueing to mix further with the anatolian peninsula, which was already hellenized at this point. I think at this point it also evidences further that both the Central Italian Roman imperial and modern southern Italian genetic structure derive their ancestry nearly totalistically from what was ultimately this cline of ancient greek ancestry rather than their original IA latin structure as well. The results of this study suggest there were no shifts of exotic input into the greek world as some have proposed but simply more movement eastwards on the preexisting Greco-anatolian cline.
Levantine ancestry hypothesis comes from looking at one too many G25 models and from some outliers in Italy who were either migrants or slaves and their ancestry didn't survive. Very similar cases can (and will) be found over time in Greece and Spain as well. We've already had clues based on modern:ancient samples as early as Lazaridis et al 2017.
arxaiogenetiki.blogspot
Regular Member
You can already see this by comparing autosomal ancestry to ancient samples and simulating how it would change if there was a large or small migration. Greece isn't easy to model for the simple reason that at first we thought there was a lot of Balkan influence but then it was found out that this was a genetic profile (slightly northern than Mycenaeans) already present in BA Greece, and then you have to take into account large and far more recent migrations of Asia Minor Greeks and Pontic Greeks which shifted the genetic landscape of several northern areas (even visible in Clemente at al 2021 plots), and without knowing which ancient samples/populations actually survived and which died out and so on.I guess we are gonna get a clear picture of the slavic and balkan genetic influence on modern greeks now with this new samples as source population for the ancient greek genome.
The only "clear picture" we're going to get is some G25 models on social media that nobody bothers looking at (definitely not the labs). Might take 5+ years to have actual papers on this subject.
arxaiogenetiki.blogspot
Regular Member
Mycenaeans are a Mediterranean but not uniform population. Some have more steppe and lower iran/chg, some have no steppe and higher iran/chg. A lot of "flunctuations" we see could simply be internal movement of pre-existing Mycenaean clans. Or not. We don't know for sure, yet.I think this research shows that the Greeks from the LBA and Iron Age started to deviate from Lazarides’ Mycenaean Greeks.
Post BA Greeks includes more samples which already had this ancestry. "Balkan-like" ancestry (e.g. Thracians) was present in Northern Greece before it was "mycenaeanised", and of course after. People get confused when they see labels like "MBA Greece" projecting modern Greek borders onto these areas, which we have no clue if they were even Greek-speaking at the time, let alone connected to Mycenaeans (they aren't). Lazaridis has mentioned more or less the same: samples in north Greece are irrelevant to Mycenaeans.Post BA Greeks certainly have more Balkan ancestry. An ancestral dimension which is mostly absent in South Italians during that time. There is also some additional steppe ancestry compared to Mycenaean Greeks.
All these could be significantly older than we detect, since various older samples do have a more elevated East Med profile. There are even Minoans that are more "Eastern" than other Minoans iirc.Also, I would suspect that the Anatolian element would increase in the Aegean side first. Such as Athens, Thebes, the Eastern islands, or rather the Athenian empire. On the other hand Corinth and Amvrasia were part of the Peloponnesian league. They avoided the Anatolian influx. This league however broke 50 years before the Macedonian empire arose. And so during the Hellenistic era Greece became more cosmopolitan in a way. The Anatolian element reached other parts of Greece as well. And after that, it gradually spread to Rome.
So as far as the increase of the Anatolian element is concerned; it starts in Asia Minor (Ionia)) —>Athenian Empire—>Hellenistic Greece —> Rome
arxaiogenetiki.blogspot
Regular Member
Based on Clemente et al 2021 you can find something like 10% CHG/Iran in N. Italy and ~15% in S. Italy. If you double it (like it was in Anatolia since around the Chalcolithic) you get 20% and 30% respectively. If we assume this included IA Anatolia then you have to likely split it in two and double the second half by adding Myceaneans, so basically 10% BA Anatolia + 20% IA Anatolia, and 12,5% BA anatolia + 25% IA Anatolia. Something like that.So you believe the Caucasus-related element was Armenian-like. How much do you think modern Italians, north, centre, south, islands, owe to this group?
The funny thing is that we might never know exactly. We might never have the most exact sources. We can get an approximation and we can use Fst and IBD but after a certain point you can't be too sure.
Vitruvius
Well-known member
- Messages
- 647
- Reaction score
- 1,201
- Points
- 91
- Ethnic group
- Italian
- Y-DNA haplogroup
- I1
- mtDNA haplogroup
- H5a1
I agree. People who are still peddling on about Levantine influence are not even paying attention to the samples and data anymore. "Eastern Mediterranean" influence in southern Europe is purely Aegean in its origin.There's no levantine ancestry (or movement in general) into Greece or Italy or any part of Europe. Some levantine-like ancestry might pop up due to a combination of sources used and the BA or/and IA Anatolian ancestry (which itself is 50% Mycenaean as confirmed by Lazaridis) that is indeed detected.
Levantine ancestry hypothesis comes from looking at one too many G25 models and from some outliers in Italy who were either migrants or slaves and their ancestry didn't survive. Very similar cases can (and will) be found over time in Greece and Spain as well. We've already had clues based on modern:ancient samples as early as Lazaridis et al 2017.